Text Classification using BERT

₹2,000.00
For a mini project on text classification using BERT (Bidirectional Encoder Representations from Transformers), you would start by selecting a dataset relevant to your classification task, such as sentiment analysis or topic categorization. Common datasets include the IMDB reviews for sentiment analysis or the 20 Newsgroups dataset for topic classification.
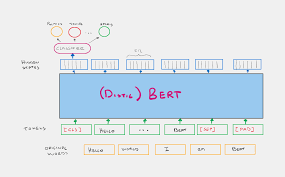
First, you would preprocess the data, which involves cleaning the text (removing special characters, stopwords, etc.) and splitting it into training and testing sets. Next, you would utilize a pre-trained BERT model from libraries like Hugging Face’s Transformers. BERT’s architecture, which understands context through bidirectional training, makes it particularly effective for text classification.
You’d fine-tune the BERT model on your training dataset, adjusting parameters like learning rate and batch size for optimal performance. After training, you would evaluate the model using metrics such as accuracy, precision, recall, and F1-score on the test set.
To visualize your results, you could create confusion matrices or classification reports. Finally, you might explore hyperparameter tuning or try different variations of BERT (like DistilBERT for efficiency) to see how they affect performance. Documenting your findings, challenges faced, and potential improvements would provide a comprehensive overview of your project.


Reviews
There are no reviews yet.