Named Entity Recognition (NER) in Legal Documents report

₹2,000.00
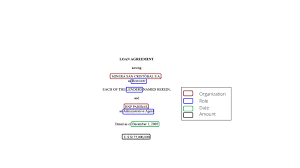
One important usage of natural language processing (NLP) in legal documents is Named Entity Recognition (NER), which focusses on locating and classifying important entities in legal texts. This procedure entails identifying key terms that are highly relevant in legal situations, such as names of people, organisations, places, legal acts, and dates. NER systems improve the effectiveness and precision of legal research and document analysis by automating the extraction of these entities. In order to learn the precise language and terminology used in the legal sector, NER models are typically trained on annotated legal datasets. This is frequently accomplished by employing sophisticated methods such as deep learning structures, such as transformers or recurrent neural networks (RNNs).
These models make it easier to extract structured information from unstructured legal documents by analysing the text and assigning entity labels to recognised phrases. Legal practitioners can swiftly find important information, evaluate risks, and guarantee regulatory compliance with the help of NER applications in contract analysis, compliance monitoring, case law research, and e-discovery. Notwithstanding its benefits, NER has drawbacks, including the intricacy of legalese and differences in writing styles. As a result, research is being done to strengthen its accuracy and robustness, which will eventually make it a useful tool for increasing workflow efficiency in the legal industry.




Reviews
There are no reviews yet.