Developing a Speech-to-Text System using Deep Learning report

₹10,000.00
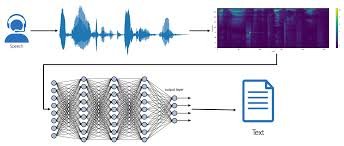
Using deep learning to develop a speech-to-text system entails building a model that reliably translates spoken words into written text. To improve model robustness, a broad dataset of audio recordings and their accompanying transcriptions is first gathered. This ensures that the dataset contains a range of accents, dialects, and background noises. One of the preprocessing procedures is feature extraction, which involves converting audio data into spectrograms or Mel-frequency cepstral coefficients (MFCCs) in order to extract pertinent acoustic characteristics. The link between audio features and text output is then learnt using deep learning architectures like transformer models or recurrent neural networks (RNNs).These models learn to predict text sequences from audio input through the use of supervised learning techniques. Metrics such as word error rate (WER), which gauges the accuracy of the transcriptions, are used to assess the system’s performance. Once created, the speech-to-text system can be included into a number of applications, including accessibility tools, virtual assistants, and transcription services, which will improve user interaction and communication in a variety of contexts.




Reviews
There are no reviews yet.