Building a Speech Synthesis Model using AI Report

₹2,000.00
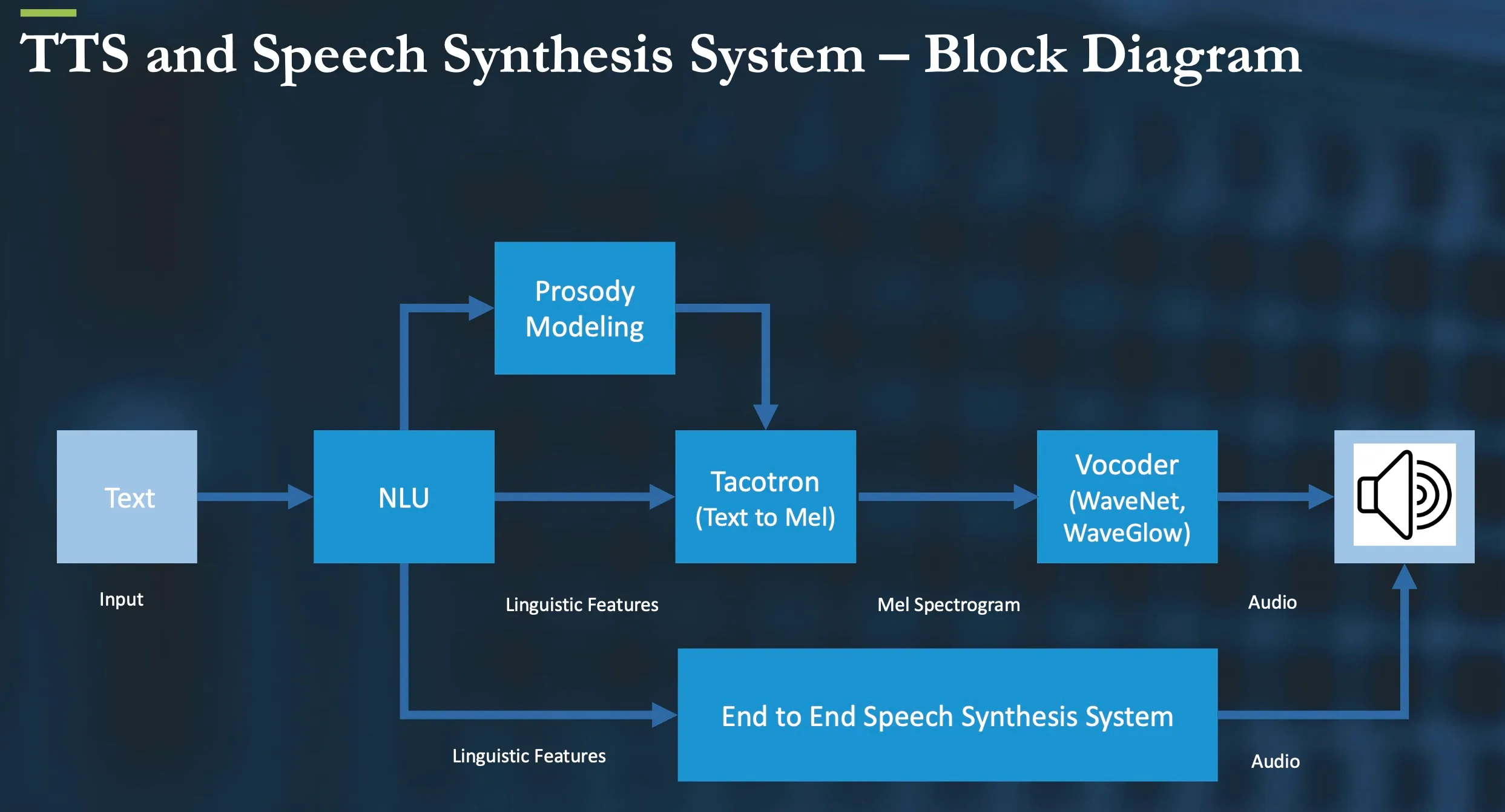
Building a speech synthesis model using AI involves several key steps, starting with data collection and preprocessing. A diverse dataset of high-quality audio recordings paired with corresponding text transcripts is essential for training the model effectively. Next, you’ll need to choose an appropriate architecture, such as Tacotron or WaveNet, which are popular for their ability to generate natural-sounding speech. Training the model requires significant computational resources, as it involves optimizing parameters to minimize the difference between generated speech and the original recordings. After training, fine-tuning the model can enhance its performance on specific voice characteristics or accents. Finally, implementing the model in a user-friendly application allows for real-time text-to-speech conversion, enabling various applications from virtual assistants to accessibility tools. Continuous evaluation and iteration are crucial to improving the model’s accuracy and expressiveness.



Reviews
There are no reviews yet.