Building a Spam Email Classifier using Naive Bayes report

₹2,000.00
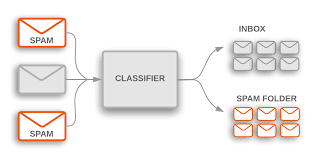
Using Naive Bayes to build a spam email classifier is a common method for removing spam by examining email content and determining if an email is “spam” or “ham” (non-spam). Because it works under the premise that each word’s existence in an email is independent of the others, Naive Bayes is very useful for this purpose. This simplifies computations and yields precise predictions for text categorisation issues.
Important Procedures for Developing a Spam Classifier Using Naive Bayes Data Gathering: Gather an email dataset that has been labelled, with each email being categorised as either spam or ham. Spam classifiers are frequently trained using popular datasets, such as the Enron Spam dataset.
Training the Naive Bayes Model: Naive Bayes uses the likelihood that a given word would appear in spam or ham emails to determine the likelihood that an email is spam. The model assumes word independence and calculates these probabilities using Bayes’ theorem. Although there are other varieties of Naive Bayes classifiers, Multinomial Naive Bayes is frequently employed for text data due to its ability to efficiently handle word frequencies.
Model Evaluation: Use measures such as accuracy, precision, recall, and F1 score to assess the classifier on test data. Because a good spam filter should reduce false positives (ham emails that are misclassified) and false negatives (spam emails that are not discovered), precision and recall are especially crucial.
Deployment: The Naive Bayes classifier can identify incoming emails as either spam or ham after it has been trained.




Reviews
There are no reviews yet.