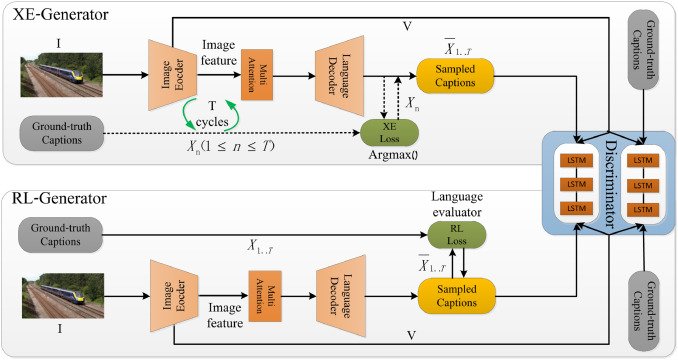
Image caption generation using Generative Adversarial Networks (GANs) involves leveraging the capabilities of GANs to create descriptive text for images. In this approach, a generator network produces captions based on visual input, while a discriminator evaluates the quality of these captions against ground truth descriptions. The generator learns to improve its output by receiving feedback from the discriminator, which helps in refining the language used to better match the content of the images. This iterative process enhances the model’s ability to understand and describe visual elements, resulting in more coherent and contextually relevant captions. By combining visual feature extraction techniques with natural language processing, GANs can effectively bridge the gap between visual data and textual representation, leading to advancements in applications like automated image tagging, content creation, and accessibility tools.




Reviews
There are no reviews yet.